

Modern use cases are demanding modern ways to deal with data. These use cases have a lot in common. For example, they all have fast-moving data at the core, mostly coming from devices. They all need modern processing data in a lot more contextual and predictive manner which will require data to be linked in graph structure coupled with many AI models working together. The era of assembling a few pieces from open source to build such systems is gone already, most of the tools and systems in the market were created decades ago. Traditional architecture is failing to cope with the requirements increasingly. This is a great time to come up with the architecture and system which is designed from the ground up to address such problems. BangDB is a converged data platform that natively integrates AI, stream, and Graph processing within the NoSQL database.
Please see this blog which covers some of these aspects as well in a nice manner
Let’s look at the simple fact. In just a few years, the majority of the data will be generated by the devices. In less than a decade, device data will grow from being less than 2% to over 50% of the global data sphere [ Ref: IDC]. This change has been extremely rapid compared to the natural growth of the other systems and tools/technologies in the market. This has created an impedance mismatch and a huge gap when it comes to tackling the emerging or even the traditional use cases in the modern context.
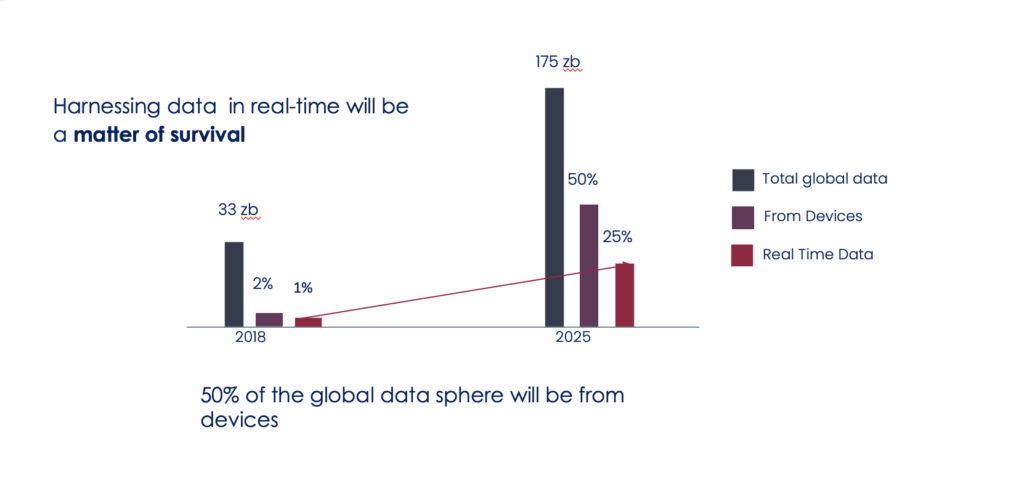
By nature, these data move fast and carry lots of valuable insights which should be mined as soon as possible for higher value extraction. Graph structure gives these data much-needed context which could be leveraged in an absolute or probabilistic manner. Native AI provides real-time prediction support for various streaming events. And, since data may have many different formats, therefore, we must have a mechanism in place to deal with unstructured data in a scalable manner.
Some of the use cases for modern data processing would be.
- Smart device data analysis for thousands to millions of such devices in a real-time and predictive manner for operational efficiency by harnessing local / edge data
- Vehicle sensor data analysis for finding or predicting anomalies, interesting patterns for safety, security, and maintenance of the vehicle
- Satellite image analysis for finding the signature of interest. UAV, SAR type image analysis for finding changes in topologies of any given area, from a security, agriculture, or climate analysis point of view
- Operational efficiency for Integrated large-scale system using various logs, sensors, devices, apps, systems, services, etc. data, all at the same time
All the above use cases involve a plethora of log/data streaming into a single system (for linking, correlation). They also require real-time stream and Graph processing and analysis. Building several machine learning models for online predictions and mechanisms to take action. On top of it, we must do all these with sub-second latency as these data have quickly diminishing intelligence value.
What are the problems with the existing systems/ architecture?
- There is a lack of convergence at the system level. If you see it from a high level, the problem is posing a challenge of convergence, by bringing too many disparate requirements to the same place. Therefore, from a solution perspective as well, we must converge to offset the problems and their challenges. Such as, we must natively integrate modern data procssing like Graph, Stream processing, AI, and unstructured data handling within the data platform. Whereas the reality is that we often deal with several silos instead of one unified platform
- Stitching too many tools or systems may not be effective. First, it may take several human resources for quarters to years to build such a system. Then enabling use cases on top of it may not be very effective. Further, such a system may not fulfill all the basic requirements. For example, copying data across multiple sub-systems, and the network overhead of bouncing packets from one place to another would simply make the latency unacceptable. Such systems would enforce many different constraints from different dimensions, for example, data could be kept in memory which will either make the proposition brittle and/or very costly
- True edge computing is required for most of these use cases. Which tells us that we must embed part of the system within the device itself. What it means is that we must have a scenario where part of the same system is deployed within the device (ARM processors) in an embedded manner where it can deal with hyper-local data analysis. The same system is deployed on the LAN or Cloud (or both) which is interconnected with all the embedded deployments within several devices. This forms a hybrid compute network which is cooperating, shares different responsibilities, and collaborates to achieve a single goal (or set of goals). Most of the existing systems or platforms in the area would not be able to do so, thereby defeating the basic need of the use cases
How does BangDB fit into such a scenario?
BangDB is a converged database that has natively implemented following
- Modern Data Processing
- Stream Processing
- Graph Processing
- Machine Learning
- Multi-model support
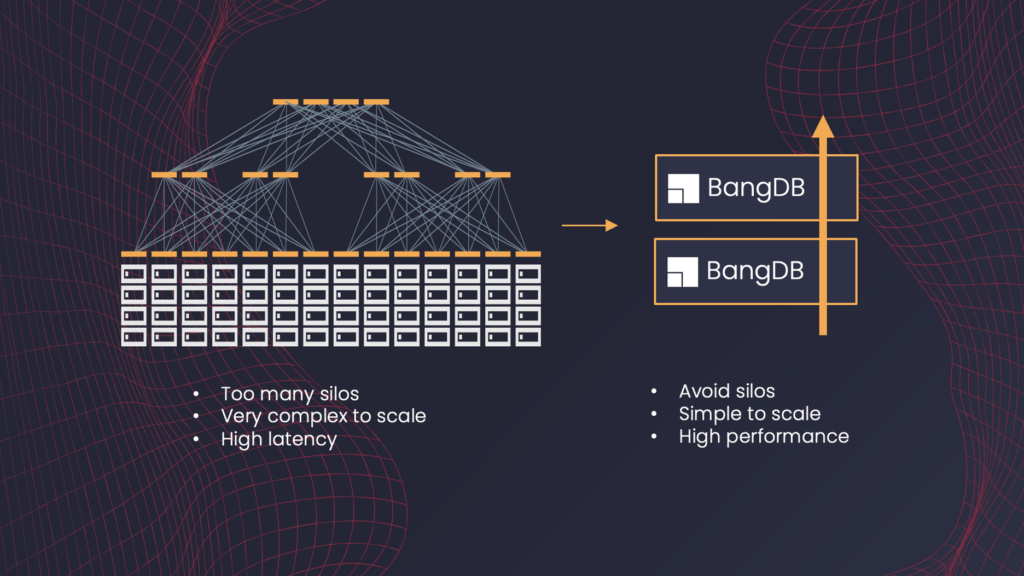
From an architectural point of view, BangDB follows the convergence model which means instead of splitting the system into multiple pieces and scaling different pieces separately, it follows space-based architecture where all necessary pieces are always in a single space, and we scale the spaces as we need. In other words, instead of 3-tier or n-tier architecture, in space-based architecture, we always deal with several units of computing (or machines) where each unit of computing contains all necessary components.
This avoids extra copy of data, network hops, distribution overhead for splitting requests, and combining responses which result in higher latency, computational overhead, and complex management apart from high cost and resource guzzling procedure. True convergence allows us to scale the system linearly without much overhead along with hyper-fast processing speed and ease of development and management.
BangDB is a full-fledged database as well, it implements some of the advanced features of a mature database like transaction, write-ahead log, buffer pool/page cache, indexes, persistence, rich query support, etc. BangDB is available free of cost, download it and start building modern apps with ease