
BangDB, the multimodal database for modern apps
BangDB Features and Benefits
BangDB Features and Benefits





 Text, Images, Videos
Text, Images, Videos Streaming Real-time
Streaming Real-time AI within Database
AI within Database Graph Processing
Graph Processing Device, Edge and Cloud
Device, Edge and CloudBangDB Features and Benefits
World's first and the only converged NoSQL Data Platform with AI, Graph processing, Streaming and multimodal data support.
World's fastest database - 2X+ performance over the traditional databases like MongoDB, Redis, Couchbase and other databases.
BangDB is built from ground-up to align with the emerging data trend for building powerful modern apps in no-code manner.

Multimodal Database
BangDB is aligned with the data trend and is designed for modern applications.
Modern apps need to deal with all kinds of data and we need a database which can truly handle different data natively in a single place.
- Stitching a platform using multiple other databases won't work.
- It takes forever for a team to ship new product, or serve clients.
- Correlation and linking of all sorts of data is very hard with different data in separate databases.
- With multimodal, the overall ops cost may go down by more than twice.
Truly Converged Database
Huge benefits due to BangDB convergence
Convergence of systems is the key so that the developers and orgs can be more productive by simply focusing on their use cases and not dealing with different kinds of databases for different data types.
Modern use cases require stream processing, graph structuring, document storage and finally AI, all at the same time and place.
- Extreme productivity - Break Silos, focus on app, accelerated time to market.
- High Performance - 2X compared to other popular databases
- Naturally Hybrid - Deploy and run anywhere. Device, Edge, Cloud etc.
- High Scale with ease - Scale linearly, vertically or horizontally.
- Huge cost reduction - Both System and ops wise, faster dev cycle.

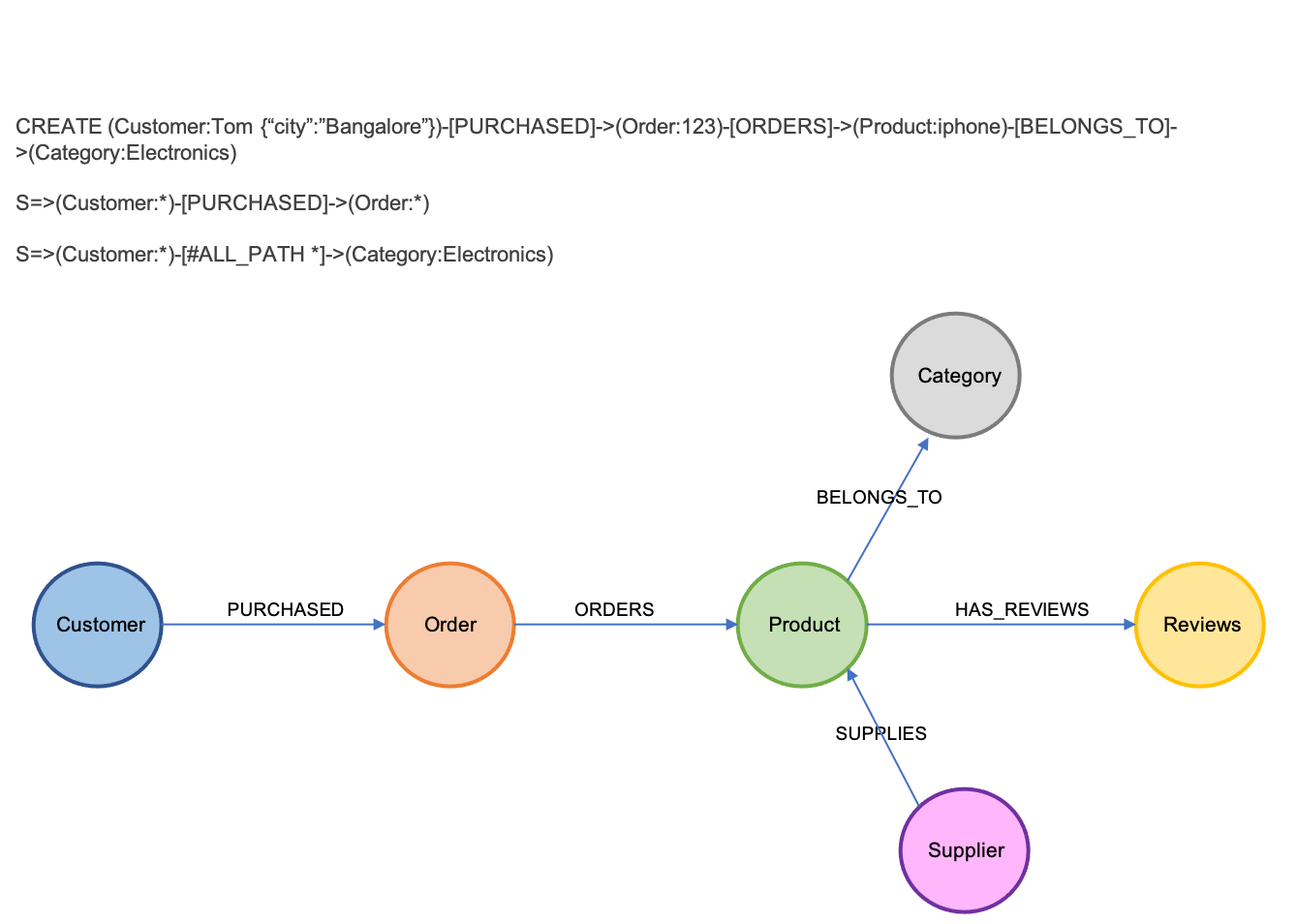
Graph and Cypher
Entity and relationships for linked events
Data is coming from all directions and there are certain relationships and links among the data which defines context and are useful for business processing and intelligence.
- Graph processing as natively integrated part of the system with schema enforcement
- Cypher/English with explicit/implicit AI for querying data from Graph directly
- Graph is internally integrated with stream processing for context-based intelligence
- Scales for large amount of data for both storage and query due to unique composite index system for storing nodes and relations
Stream processing
Real-time continuous data intelligence
Rise of real time data pushes for real time streaming and predictive data analytics for advanced and optimized business operations.
- Continuous ingestion of time-series events from anywhere, any device, or systems
- Sliding window (continuous) for limitless continuous processing of the time-series events
- Running aggregates and statistics, training, prediction on streaming data
- Complex Event Processing, anomaly & pattern detection in real time
- Auto action from the stream processing layer
- Handle large amount of data using much lesser resources


Integrated AI
BangDB has natively integrated AI which allows AutoML to the users for various database activities
BangDB has inbuilt AI capabilities and provides APIs and tools to the users to deal with model training, deployment, prediction and measurement.
- Train data within database, test, deploy and automate the process
- AI integrated with query language which does all the work behind the scene and returns data as required
- AI is part of stream processing construct which helps enriching the data with models in real time manner
- Pattern analysis to information extraction to some deep learning activities are available as part of the database constructs
- BangDB implements resource server to keep these models and other large data or objects for AI as required
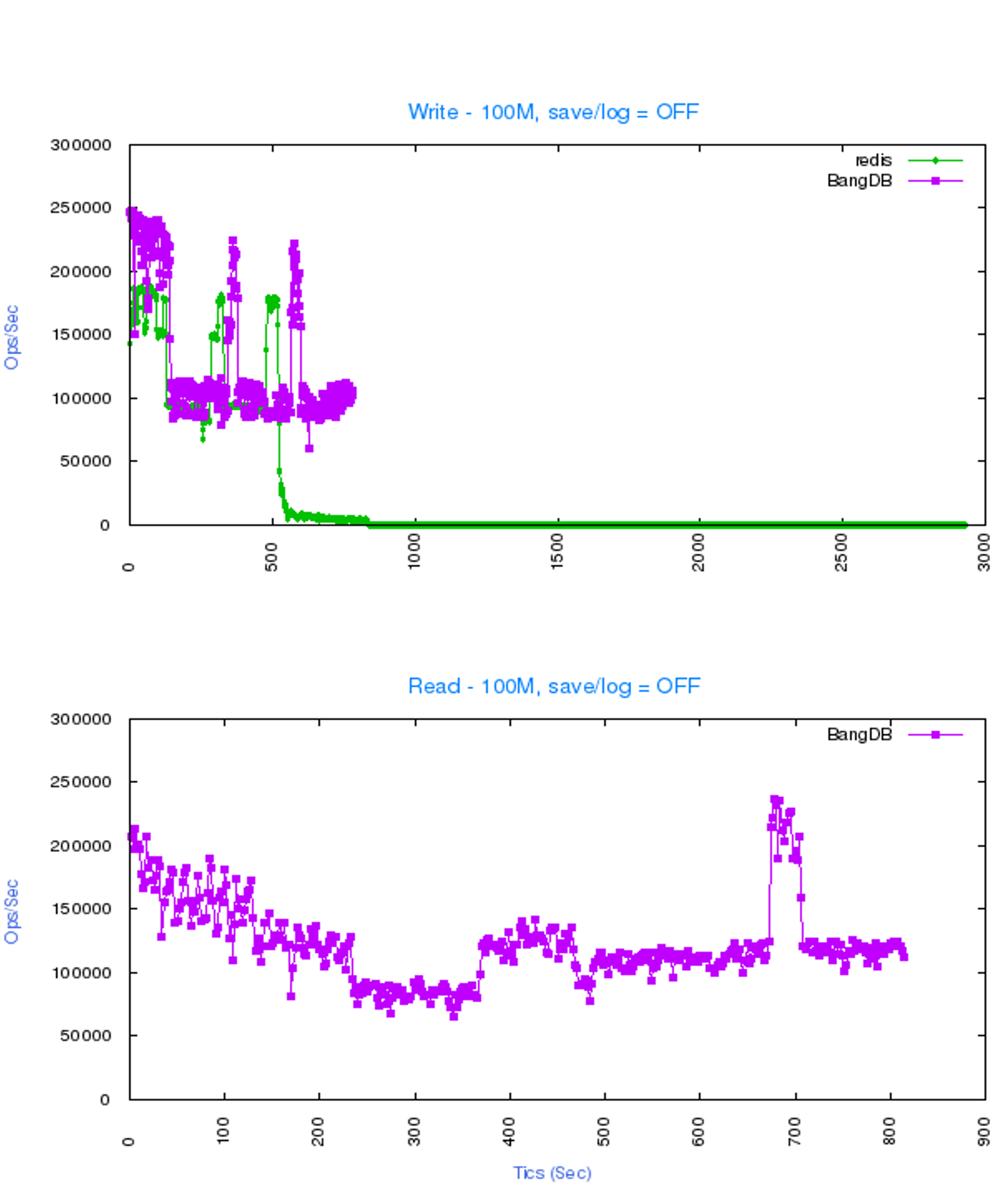
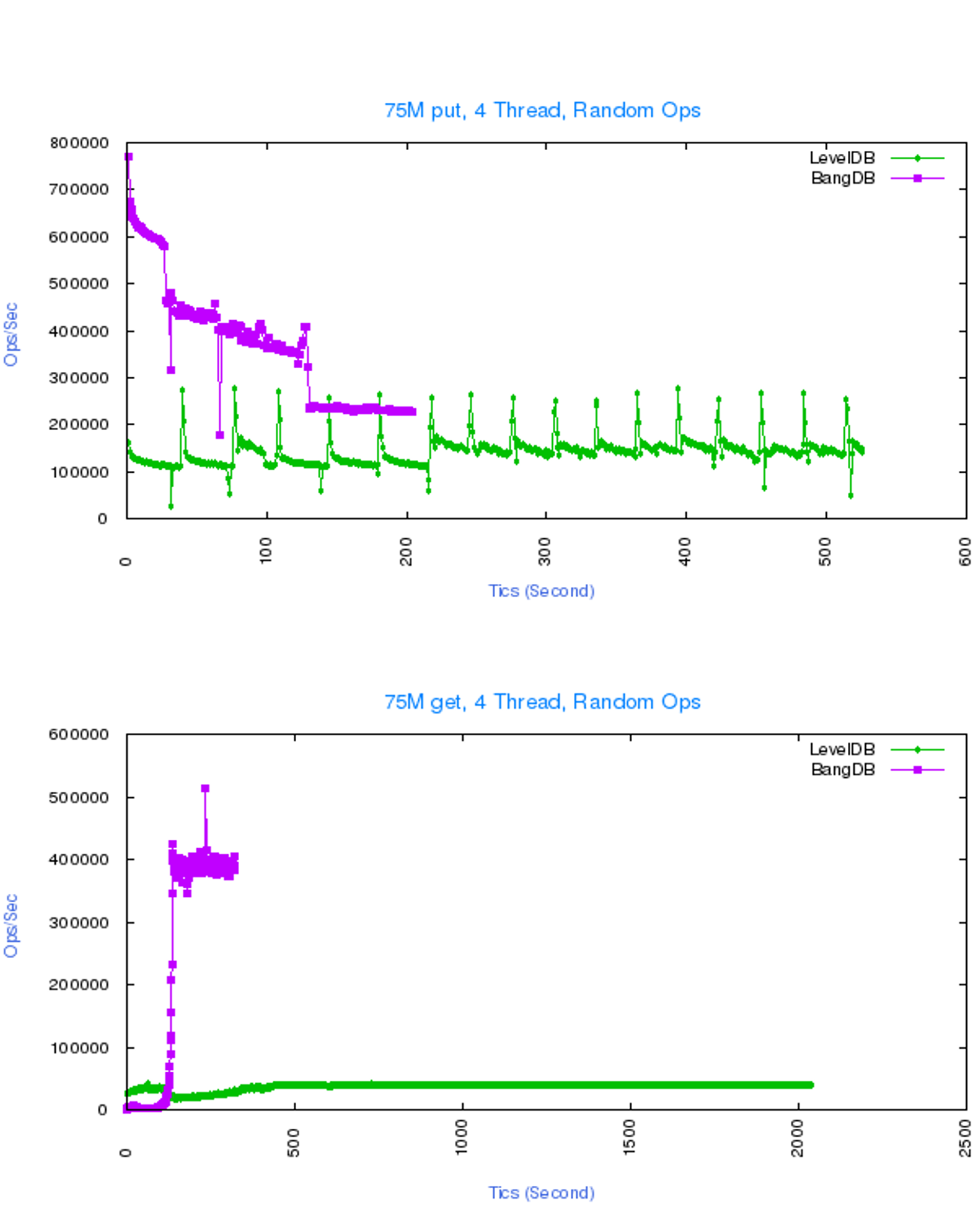
High performance.
2X+ more performance than most of the leading DBs in the market
BangDB is truly concurrent which leverages the machine in best way, for both read and write. Unlike other popular dbs in the market, BangDB implements core database features for performance, robustness, scale and security.
- Predictive buffer pool, page cache, adaptive IO Layer and SSD as RAM+ to achieve insanely high performance
- Written in C, with its own memory handling and event driven design (SEDA) to support several tens of concurrent connections for higher throughput per vm
- Several indexing techniques to enhance the query performance at scale for large amount of data beyond available memory
- Robust and battle ready with data replication, crash recovery, fine grained security and loads of automations and developer tools

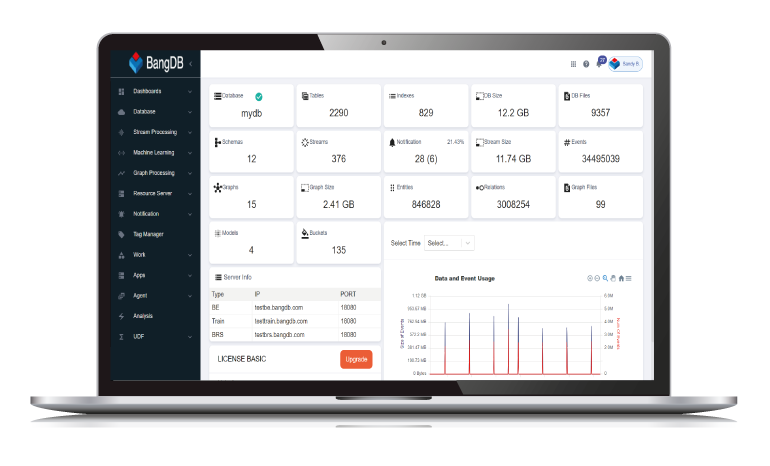
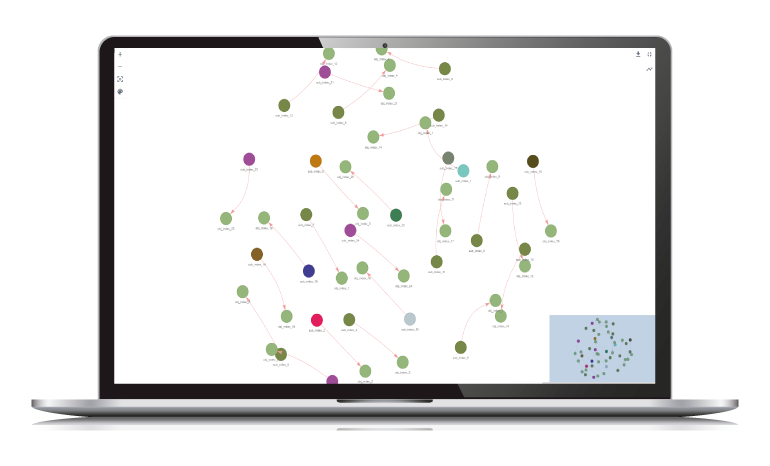
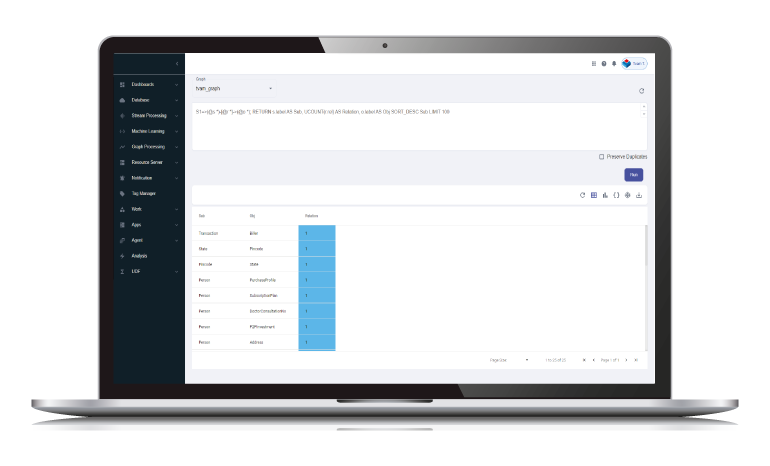
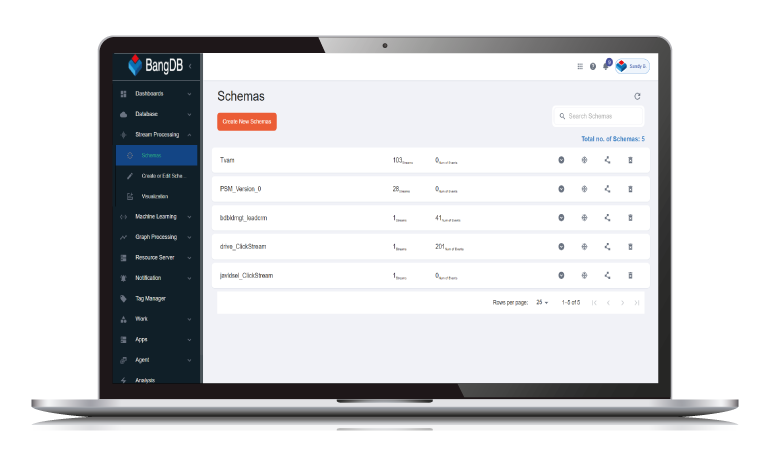

Ampere
No-code platform for building apps and enabling use cases
Ampere is a no-code platform on cloud built on top of BangDB which makes it super easy for users to solve problems, build use cases without doing any coding.
- Train data within database, test and deploy. And automate the process
- AI integrated with query language which does all the work behind the scene and returns data as required
Apps and App Store
Powerful pre-baked apps to get you started in few minutes
- BangDB publishes built in apps on the Appstore for users to get started within a few minutes for a specific set of use cases in different domains.
- We actively develop apps and can also collaborate with users and customers to do so as required by them.
- Lead management, Lead Selling, Online Forum, Bug Tracker, App and Infra Monitoring, Visitor analysis, Ecommerce analysis etc. are some of the apps available on AppStore.
- In the future, we will allow users to build custom apps, publish on the app store and monetize.

Case Studies
Checkout these real world use cases where BangDB has proven to be a game changer for our clients.
Testimonials
"IQLECT has worked on initial ontology project for Cisco product and support pages to help automate processes in the CRM team. An integrated ML/IE layer gives our solution a much-needed edge. We foresee lots of potential going forwardand look forward to a much deeper engagement with them."
 Amit DCISCO
Amit DCISCO"Based on my experience as a CTO, BangDB is a fantastic database solution which offers high performance, scalability, and reliability. Powerful APIs and broad set of features made it easy to integrate into our solutions. I appreciate the level of support and documentation provided by the BangDB team. The collaboration was truly exceptional and we managed to tune the database exactly the way we needed. Overall, I have had a great experience using BangDB and would highly recommend it to others for their data storage & real-time processing need"
 Tomasz HanusiakSenior Software Engineer, IBM
Tomasz HanusiakSenior Software Engineer, IBM"BangDB is a product that has good potential to cater to the real-time data analysis needs of an organization. The NOSql database provides you with a much more efficient alternative to the traditional relational database system like Microsoft SQL. The data is readily interconnected and ripe for the taking by any big data ingestion systems. The support from the BangDB team has been very responsive and reliable. It has made the adoption of their product much much easier. Overall, I'm looking forward to utilize BangDB to the best of its capability to help in achieving our organization's goals."
 Rahul AhujaTVAM
Rahul AhujaTVAM"We partnered with IQLECT to develop an end-to-end marketing automation and lead generation app which increased the conversion rate by 2x and generated 15% more incremental leads. IQLECT is the next best thing for the next best action. IQLECT purpose-built NoSQL, BangDB brings a convergence of AI and streaming to enable hyper real-time scenarios which are needed to solve such advanced problems. We did not find any other vendor who could match the business outcomes generated by IQLECT."
 Haider KhanAccenture
Haider KhanAccenture